Overview of search
Search Architecture
Executing Queries
Search Verticals
Custom Entity Extraction
Parser
Web service Call –out
Overview of Search
Below image shows all the different products we had
up till now. In O14 we had SharePoint Search and FAST Search. Both the products
had their own strength and weakness.
So focus of SharePoint search was on
Enterprise while FAST was search application platform. SharePoint search came
with SharePoint, so we didn't had to buy anything additional and FAST was much
about having scalability for internet site with ability to handle large catalogs. So we had these 2 products and there was a constant tag-for on which one to
use.
Now in SharePoint 2013, we only have one product to worry
about. FAST search and Enterprise search
has been unified into a single extensible platform and the idea was to take the
best from both of these products and bring them together. Now the FAST Engine
is married to SharePoint crawler.

Extensible Search Platform

- Enterprise Search
- People Search
- Site Search
- Video/Media Search
- Topics Pages and Content by Search are new WCM Feature that allow create search driven sites. So when we are creating internet sites that are driven by products, then this allows us to create these pages easily and have them dynamically populated based on products that somebody is interested
- My Tasks – In previous version we had to create custom component to fetch tasks for user from various sites. My Tasks pulls all the tasks in different sites together which can also be a part of social networking feature in user’s my site.
- Customer and partners represent search that we can extend to build out own custom applications.
Search Architecture
One of the biggest differences in Enterprise and FAST search was enterprise Search is based on INDEX being created by crawler. So crawler goes through the content and builds up an index and it is the index that gets searched.
FAST on the other hand didn't crawl. It allowed push into the index known as content API So you build up an index in FAST by taking content and pushing it into the index.
In Search 2013, Content API is gone. To get the latest SharePoint 2013 content we have new feature called continuous crawl, which keeps the index updated. Continuous crawl is only for SharePoint index and not for other content sources. Continuous crawl runs in parallel, so it does not wait for previous thread to complete before starting a new one. Continuous Crawl refers to change logs. Continuous crawl does not retry any errors generated during the crawl, so Incremental and full crawl is also necessary for Search. So you can have a vision of continuous crawl running continuously, incremental crawl running every night and full crawl running once a week.
Managed property functionality remains the same where we map crawl property with managed property to create keyword query searches against the index.

- Content Sources: Search architecture needs to connect to different content source and get access to the content. Search engine needs to take individual pieces of content from the content source and crawl through to create an index. Connecting to various content sources is done through .Net assembly connectors and working though the content (document) is called a parser.
- Parser is new piece added to 2013 which is similar to iFilter which was used in SharePoint 2010 to index content in the repository.
- Content Pipeline and CTS Run-time really just represent the functionality of bringing in content through the crawl. CTS Run-time has no extensibility functionality and works internally out of the box. There is no API provided to us to talk to Content pipeline except there is one entry point called web service callout which we will discuss later.
- Indexing Engine is just a box that represents actual Indexing of content that builds up the index that we will search
- Analyzer is used to process user behavior, perform click analysis and supports things like recommendations based on behavior. So search results are presented to anybody based on their behaviors.
- Query engine itself is responsible to execute queries against the index.
- Query Pipeline and IMS Run-time are representation of code and functionality necessary to execute that query and move it from user interface
- At Query pipeline level search provides RESTful interface, its REST API gives us way to execute query against index.
- Client framework representation CSOM, so we can use CSOM to execute queries as well.
Using CSOM API we can import and export search settings from
DEV to QA to PROD. So we don’t need to write powershell scripts to configure
Search anymore. Rule, sources and managed properties can be export but not masterpages,
templates or web parts. EG: we cannot export search result page where we have
Search Core Result web part configured.
Executing Queries

In SharePoint 2013 search, all above query syntax are unify together so
that we have fewer things to worry about.
Keyword Query Syntax is preferred method for executing query
against index. It allows us to take manage property and say managed property
equal a value eg: Title = SharePoint or Title;SharePoint means Title contains
SharePoint. This is basics of keyword query syntax.There are lot of improvement done in Keyword query syntax.
We don’t need to use any other query syntax in Search 2013.Everything that is been used in FAST query syntax is now
available in Keyword query syntax. SQL query syntax is removed from the product.
REST

This slide shows REST based API into search. So as
developers we can use the keyword query syntax into REST based API to get
results. So under the keyword section here, you see there is a URL, where there
is _api which is pointing to REST full API endpoint search query and then we
provide query string argument that refer to keyword query syntax that we want
to use. Executing RESTful based query against the search engine is a simple as
taking your KQL query and inserting right there in placeholder and you will get
result back from the search engine. Any property that was part of keyword query
object inside of SharePoint as exposed by REST as query string.In second
example above we have selecting properties where we have select property which only returns Title and Rank. Similarly we have example of sorting.

The idea with query throttling is, if you are in multi-tenant
environment, it’s important to prioritize and even throttle the queries because there could be lot of demand on the search server and tenants should not impact each other’s performance in same environment. OOB in on premises,
query throttling is off by default. The way it
works is through the concept of client type. Client type is a mechanism of
throttling incoming queries. Client type will assign Search center as P1 priority and custom apps using search query as P3. The
throttling being based on query latencies, if the search engine is working very
hard to answer lot of queries and there are latencies involved, than lower
priorities calls (P3) will receive message “System is too busy try again later”.
Add Content Search Web Part on the page as shown below

In this web part we have to configure couple of parameters.
Configure Query as shown in below screenshot

Previous in SharePoint 2010, we had to modify xsl of web part to change the look and feel. Now in SharePoint 2013, we modify html display template to change the look and feel.
Change the look and feel of the web part by uploading custom display template Item_ThreeLines-Demo.html under
Site Settings -> Master Pages and Page Layouts -> Display Templates -> Content Web parts.
In Content Search web part properties. Select the display template from the drop down and change the mapping of managed properties for the fields in the Item Display Template as shown in screenshot below.

We have come across search verticals before in Google or Bing. In previous version we had to do lot of
customization to create these search verticals. In Search 2013 we just have to
do some configuration steps to achieve it.
Below is the Production list, whose below crawl properties mapped with managed properties
Region – RegionOWS
Item – ItemOWS
Total – TotalOWS

You will already find OOB search verticals in your search center site. To create a new custom search vertical below are the steps.
Create Search Vertical called ‘Production’ by creating new page from “Search Results” page layout. Publish this page and add new search navigation link under Site Settings -> Search Settings
Create Search Vertical called ‘Production’ by creating new page from “Search Results” page layout. Publish this page and add new search navigation link under Site Settings -> Search Settings

Below is how ‘Production’ search vertical will look like after we configure couple of things shown in next few screens.

Create Result source @ site settings -> Result Source. Click on Query Builder to create query transform which would display only results from Production list
Note: Result source in SharePoint 2013 is similar to Scopes we had in SharePoint 2010.
Note: Result source in SharePoint 2013 is similar to Scopes we had in SharePoint 2010.
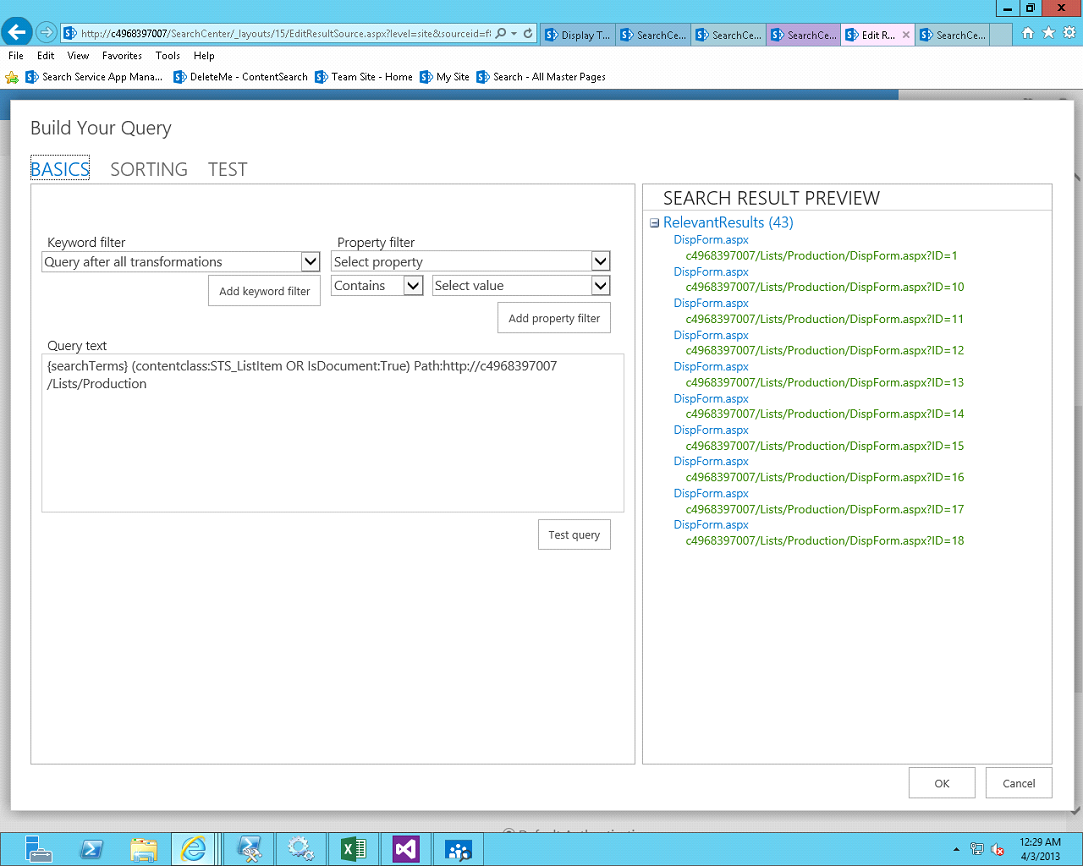
Create display template (DefaultProduction.html) and upload it @ Site Settings -> Master pages and page layouts -> Display Templates -> Search. During upload of this display template, on ItemUpdating/ItemUpdated event its corresponding javascript file is generated by SharePoint internally which is used to modify the look and feel of the web part.
Edit Search Results web part properties on Production Search Result page, click on “Change Query” button. Attach ‘Production’ result source as show below

Also attach the display template “Default Production” and add the managed properties which you would like to display in search results in “Hit Highlighted Properties” as shown below

Now in Everything search vertical, out of thousands of items in Production list, I would like to display only couple of items in Result Block search results and than continue with rest of the results from the site excluding Production list. Below is how, this is configured.
Configure Everything search vertical with Query rule to create Result Block which contains only 2 items from Production list. Create a query rule against “Local SharePoint Results” Result Source which is associated with Everything search vertical. Below is the screenshot for the same.
Site Settings -> Query Rule -> Select “Local SharePoint Results” in dropdown -> New Query Rule

Add Result Block

To create a refiners in search result page we need to map a crawl property (list column) with managed property. Custom Entity Extraction comes into picture if we do not have crawl property but still we want to create refiners on search result page. For example, we want to refine search results based on the content of documents in document library. With custom entity extraction we can plug our own
dictionary of crawl properties into search system. This dictionary is a simple .csv file which we import using powershell.
Below we have configured Technologies refiner using Custom Entity Extraction and Companies refiner using OOB Extraction.
Note: We are filtering documents based on the content (body managed property) inside the documents.

Create Technologies.csv file in key and display form format.

Import this *.csv file and attach it to one of 12 custom extraction directories.

In Central Administration -> Search Service Application -> Search Schema -> Search for ‘Body’ managed property-> Edit ->

Execute full crawl
Edit Refinement web part on Results.aspx and click “Choice Refiners”

Whenever we access content source and crawl it, we need 2
things. First we need ability to access the content source and secondly we need
ability to crawl items inside them. We had mention that we use .Net assembly
connect to crawl inside external content source and use parser to crawl
individual items that we find there.
Parser is more sophisticated than iFilter where we have 2
concepts. Parser and format handler. Parser detect the document format and does
not rely on document extension to identify the document type. Than it calls
appropriate format handler to do the parsing. Now OOB Parser can detect more
document formats than supported by format handler so iFilter are not gone
complete. Wherever Parser does not find appropriate format handler it will
revert back to calling iFilter to do the parsing.
Deep link extraction identifies relevant headers in
documents and display header and its corresponding content in as preview when
we hover on search result link.
Visual Meta data extraction pulls title authors and dates
instead of relying on metadata properties.
Allows you to modify manage property and also add or delete
one, before the crawling is completed. We can use them for data cleansing. Eg: People are tagging document with
company information. So some people will write MS for Microsoft or Microsoft
corporation for Microsoft. So using web service call out mechanism we can
normalize this data to Microsoft. We can also add new managed properties before
the crawling is completed.



2 comments:
Very useful post. Thanks
Nice Post!
Post a Comment